地端建立 Ollama 服務
BUBU 因為想要自建屬於自已的 LLM 服務,剛好之前陣為了 AI 服務而買了一張 NVIDIA P4 GPU 運算的設備來測試,那剛好最近有空閒已將該服務成功建立在 Linux 環境上運行, BUBU 使用 Ollama 開源服務建置
運行環境
環境都是在 「Proxmox VE 」 虛擬系統上架設,都是以 「 LXC 」模式為主,除非有特殊狀況會告知使用 「 VM 」 模式
- 系統環境: Debian 12
安裝過程
安裝顯示卡服務
如果您是用 Proxmox VE 顯示分享方式,如果遇到 kernel 有做更新的話,那您需要再次重新安裝 Nvidia 的驅動之後再重新設定 kernel 服務重啟母機就可以正常使用了。
BUBU 因為運行的環境是在 LXC 上面,所以在那安裝 Ollama 服務之前先設定有 Proxmox VE 顯卡服務這樣子有用到 LXC 服務需要顯示卡功能可以分享使用。
- 可以參考本站所編寫的文章下去設定 LXC 直通顯示卡 - PVE 8
安裝 Ollama 服務
- 如果您環境已有安裝好顯示卡驅動及
CUDA服務可以直接到官方複製一段指令之後就會自動幫您安裝好相關服務及套件
curl -fsSL https://ollama.com/install.sh | sh
- 如果您的
Ollama是獨立運行要讓其他服務透過API跟您的站台連線那您需要在啟動服務的時候一起設定遠端服務也是可以連線
vim /etc/systemd/system/ollama.service
# 新增以下參數
[Service]
Environment="OLLAMA_HOST=0.0.0.0"
- 重新載入服務設定檔
systemctl daemon-reload && systemctl restart ollama
- 在用瀏灠器確定是否有可以連上該服務
http://Ollama 位置:11434連線成功會在畫面上看到這段文件
Ollama is running
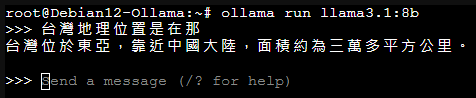
- 在指令列上手動啟用模型,如果您沒有下載過模型的話,系統在啟用該模型會先下載再啟用
ollama run llama3.1:8b
- 啟用該模型的對話樣子

- 在用指令列上詢問測試,結果如下